What is Katana?
Katana is a command-line interface (CLI) web crawling tool written in Golang. It is designed to crawl websites to gather information and endpoints. One of the defining features of Katana is its ability to use headless browsing to crawl applications. This means that it can crawl single-page applications (SPAs) built using technologies such as JavaScript, Angular, or React. These types of applications are becoming increasingly common, but can be difficult to crawl using traditional tools. By using headless browsing, Katana is able to access and gather information from these types of applications more effectively.
Katana is designed to be CLI-friendly, fast, efficient and with a simple output format. This makes it an attractive option for those looking to use the tool as part of an automation pipeline. Furthermore, regular updates and maintenance ensure that this tool remains a valuable and indispensable part of your hacker arsenal for years to come.
Tool integrations
Katana is an excellent tool for several reasons, one of which is its simple input/output formats. These formats are easy to understand and use, allowing users to quickly and easily integrate Katana into their workflow. Katana is designed to be easily integrated with other tools in the ProjectDiscovery suite, as well as other widely used CLI-based recon tools.
What is web crawling?
Any search engine you use today is populated using web crawlers. A web crawler indexes web applications by automating the “click every button” approach to discovering paths, scripts and other resources. Web application indexing is an important step in uncovering an application’s attack surface.
Installation
Katana allows a couple of different installation methods, downloading the pre-compiled binary, compiling the binary using go, or docker.
Binary
There are two ways to install the binary directly onto your system:
- Download the pre-compiled binary from the release page.
- Run go install:
go install github.com/projectdiscovery/katana/cmd/katana@latestDocker
- Install/Update docker image to the latest tag
docker pull projectdiscovery/katana:latest2. Running Katana
a. Normal mode:
docker run projectdiscovery/katana:latest -u https://tesla.comb. Headless mode:
docker run projectdiscovery/katana:latest -u https://tesla.com -system-chrome -headlessOptions
Here are the raw options for your perusal – we'll take a closer look at each below!
Configuration
-d, -depth Defines maximum crawl depth, ex: -d 2 Enables endpoint parsing/crawling from JS files
-jc, -js-crawl-ct, -crawl-duration Maximum time to crawl the target for, ex: -ct 100 Enable crawling for known files, ex:
-kf, -known-filesall,robotstxt,sitemapxml, etc. Maximum response size to read, ex:
-mrs, -max-response-size-mrs 200000 Time to wait for request in seconds, ex:
-timeout-timeout 5 Enable optional automatic form filling. This is still experimental
-aff, -automatic-form-fill-retry Number of times to retry the request, ex: -retry 2 HTTP/socks5 proxy to use, ex:
-proxy-proxy http://127.0.0.1:8080 Include custom headers/cookies with your request, ex:
-H, -headersTODO Path to the katana configuration file, ex:
-config-config /home/g0lden/katana-config.yaml Path to form configuration file, ex:
-fc, -form-config-fc /home/g0lden/form-config.yaml
Headless
-hl, -headless Enable headless hybrid crawling. This is experimental-sc, -system-chrome Use a locally installed Chrome browser instead of katana’s-sb, -show-browser Show the browser on screen when in headless mode-ho, -headless-options Start headless chrome with additional options-nos, -no-sandbox Start headless chrome in --no-sandbox mode
Scope
-cs, -crawl-scope In-scope URL regex to be followed by crawler, ex: -cs login Out-of-scope url regex to be excluded by crawler, ex:
-cos, -crawl-out-scope-cos logout Pre-defined scope field (dn,rdn,fqdn), ex:
-fs, -field-scope-fs dn Disables host-based default scope allowing for internet scanning
-ns, -no-scope-do, -display-out-scope Display external endpoints found from crawling
Filter
-f, -field Field to display in output (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir), ex: -f qurl Field to store in selected output option (url,path,fqdn,rdn,rurl,qurl,qpath,file,key,value,kv,dir,udir), ex:
-sf, -store-field-sf qurl Match output for given extension, ex:
-em, -extension-match-em php,html,js Filter output for given extension, ex:
-ef, -extension-filter-ef png,css
Rate-limit
-c, -concurrency Number of concurrent fetchers to use, ex: -c 50 Number of concurrent inputs to process, ex:
-p, -parallelism-p 50 Request delay between each request in seconds, ex:
-rd, -delay-rd 3 Maximum requests to send per second, ex:
-rl, -rate-limit-rl 150 Maximum number of requests to send per minute, ex:
-rlm, -rate-limit-minute-rlm 1000
Output
-o, -output File to write output to, ex: -o findings.txt Write output in JSONL(ines) format
-j, -json-nc, -no-color Disable output content coloring (ANSI escape codes)-silent Display output only-v, -verbose Display verbose output-version Display project version
Different inputs
There are four different ways to give katana input:
- URL input
katana -u https://tesla.com2. Multiple URL input
katana -u https://tesla.com,https://google.com3. List input
katana -list url_list.txt4. STDIN input (piped)
echo “https://tesla.com” | katanaCrawling modes
Standard mode
Standard mode uses the standard Golang HTTP library to make requests. The upside of this mode is that there is no browser overhead, so it’s much faster than headless mode. The downside is that the HTTP library in Go analyzes the HTTP response as is and any dynamic JavaScript or DOM (Document Object Model) manipulations won’t load, causing you to miss post-rendered endpoints or asynchronous endpoint calls.
If you are confident the application you are crawling does not use complex DOM rendering or has asynchronous events, then this mode is the one to use as it is faster. Standard mode is the default:
katana -u https://tesla.comHeadless mode
Headless mode uses internal headless calls to handle HTTP requests/responses within a browser context. This solves two major issues:
- The HTTP fingerprint from a headless browser will be identified and accepted as a real browser – including TLS and user agent.
- Better coverage by analyzing raw HTTP responses as well as the browser-rendered response with JavaScript.
If you are crawling a modern complex application that utilizes DOM manipulation and/or asynchronous events, consider using headless mode by utilizing the -headless option:
katana -u https://tesla.com -headlessControlling your scope
Controlling your scope is important to returning valuable results. Katana has four main ways to control the scope of your crawl:
- Field-scope
- Crawl-scope
- Crawl-out-scope
- No-scope
Field-scope
When setting the field scope, you have three options:
- rdn - crawling scoped to root domain name and all subdomains (default)
- Running
katana -u https://tesla.com -fs dnreturns anything that matches *.tesla.com
- fqdn - crawling scoped to given sub(domain)
a. Running katana -u https://tesla.com -fs fqdn returns nothing because no URLs containing only “tesla.com” are found
b. Running katana -u https://www.tesla.com -fs fqdn only returns URLs that are on the “www.tesla.com” domain.

- dn - crawling scoped to domain name keyword
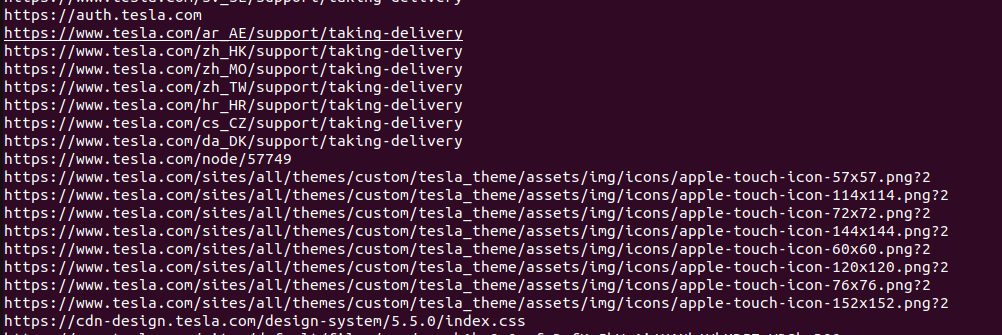
a. Running katana -u https://tesla.com -fs dn returns anything that contains the domain name itself. In this example, that is “tesla”. Notice how the results returned a totally new domain suppliers.teslamotors.com

Crawl-scope
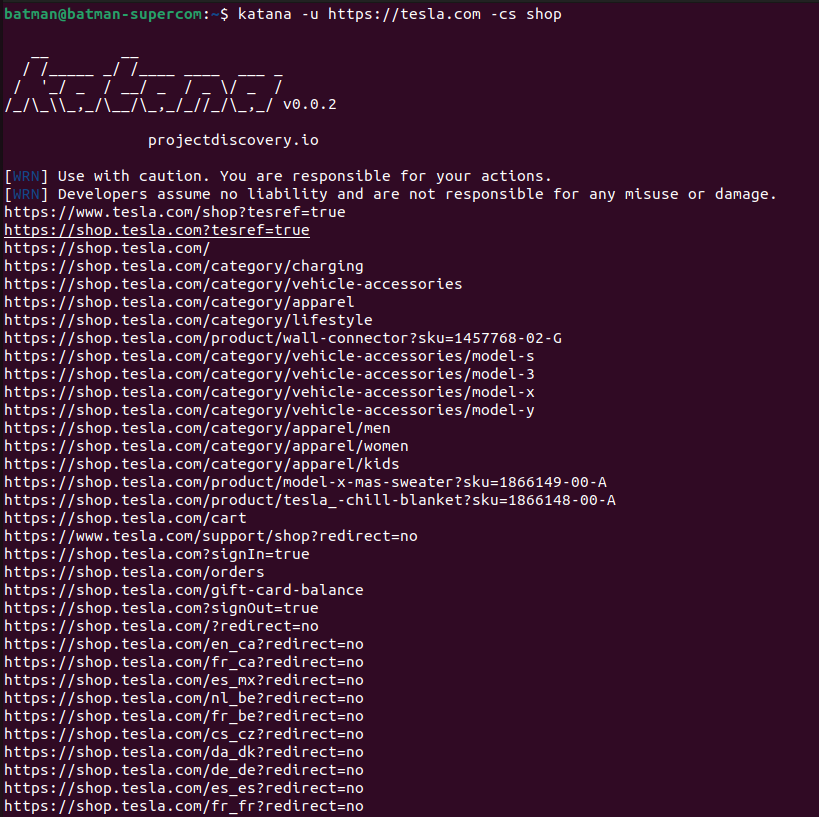
The crawl-scope (-cs) flag works as a regex filter, only returning matching URLs. Look at what happens when filtering for “shop” on tesla.com. Only results with the word “shop” are returned.
Crawl-out-scope
Similarly, the crawl-out-scope (-cos) flag works as a filter that will remove any urls that match the regex given after the flag. Filtering for “shop” removes all urls that contain the string “shop” from the output.

No-scope
Setting the no-scope flag will allow the crawler to start at the target and crawl the internet. Running katana -u https://tesla.com -ns will pick up other domains that are not on the beginning target site “tesla.com” as the crawler will crawl any links it finds.

Making Katana a crawler for you with configuration
Depth
Define the depth of your crawl. The higher the depth, the more recursive crawls you will get. Be aware this can lead to long crawl times against large web applications.
katana -u https://tesla.com -d 5Crawling JavaScript
For web applications with handfuls of JavaScript files, turn on JavaScript parsing/crawling. This is turned off by default, but turning this on will allow the crawler to crawl and parse JavaScript files. These files can be hiding all kinds of useful endpoints.
katana -u https://tesla.com -jcCrawl duration
Set a predefined crawl duration and the crawler will return all URLs it finds in the specified time.
katana -u https://tesla.com -ct 2Known files
Find and crawl any robots.txt or sitemap.xml files that are present. This functionality is turned off by default.
katana -u https://tesla.com -kf robotstxt,sitemapxmlAutomatic form fill
Enables automatic form-filling for known and unknown fields. Known field values can be customized in the form config file (default location: $HOME/.config/katana/form-config.yaml)
katana -u https://tesla.com -affHandling your output
Field
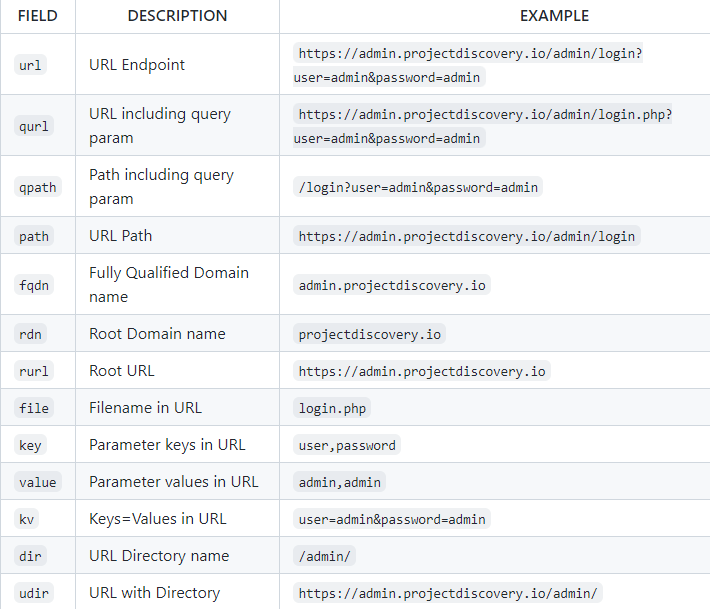
The field flag is used to filter the output for the desired information you are searching for. ProjectDiscovery has been kind enough to give a very detailed table of all the fields with examples:
Look what happens when filtering the output of the crawl to only return URLs with query parameters in it:

Store-field
The store-field flag does the same thing as the field flag we just went over, except that it filters the output that is being stored in the file of your choice. It is awesome that they are split up. Between the store-field flag and the field flag above, you can make the data you see and the data you store different if needed.
katana -u https://tesla.com -sf key,fqdn,qurlExtension-match & extension-filter
You can use the extension-match flag to only return urls that end with your chosen extensions
katana -u https://tesla.com -silent -em js,jsp,jsonIf you would rather filter for file extensions you DON’T want in the output, then you can filter them out of the output using the extension-filter flag
katana -u https://tesla.com -silent -ef css,txt,mdJSON
Katana has a JSON flag that allows you to output a JSON format that includes the source, tag, and attribute name related to the discovered endpoint.

Rate limiting and delays
Delay
The delay flag allows you to set a delay (in seconds) between requests while crawling. This feature is turned off by default.
katana -u https://tesla.com -delay 20Concurrency
The concurrency flag is used to set the number of URLs per target to fetch at a time. Notice that this flag is used along with the parallelism flag to create the total concurrency model.
katana -u https://tesla.com -c 20Parallelism
The parallelism flag is used to set the number of targets to be processed at one time. If you only have one target, then there is no need to set this flag.
katana -u https://tesla.com -p 20Rate-limit
This flag allows you to set the maximum number of requests that the crawler is sending out per second
katana -u https://tesla.com -rl 100Rate-limit-minute
A rate-limiting flag similar to the one above, but used to set a maximum number of requests per minute.
katana -u https://tesla.com -rlm 500Chaining Katana with other ProjectDiscovery tools
Since katana can take input from STDIN, it is straightforward to chain katana with the other tools that ProjectDiscovery has released. A good example of this is:
subfinder -d tesla.com -silent | httpx -silent | katanaConclusion
Hopefully, this has excited you to go out and crawl the planet. With all the options available, you should have no problem fitting this tool into your workflows. ProjectDiscovery has made this wonderful web crawler to cover many sore spots created by crawlers of the past. Katana makes crawling look like running!
Author – Gunnar Andrews, @g0lden1